Deploy DeepSeek R1 with Azure AI Foundry and Gradio
In this walkthrough, I’ll show you how to deploying create a “thinking LLM” chat interface with thought bubbles using DeepSeek R1, Azure AI Foundry SDK, and Gradio.
This post is based on a Jupyter notebook example I created. You can use it alongside this walkthrough. Find it here: DeepSeek R1 with Azure AI Foundry and Gradio
Table of Contents
- Introduction
- DeepSeek R1 on Azure AI Foundry
- Benefits of Using DeepSeek R1 on Azure AI Foundry
- Prerequisites
- Setting Up the ChatCompletionsClient
- Implementing a Streaming Response Function
- Creating the Gradio Interface
- Conclusion
Introduction
![]()
DeepSeek R1 has gained widespread attention for its advanced reasoning capabilities, excelling in language processing, scientific problem-solving, and coding. With 671B total parameters, 37B active parameters, and a 128K context length, it pushes the boundaries of AI-driven reasoning (Explore DeepSeek R1 on Azure AI Foundry). Benchmarking and evaluation results highlight its performance against other models, showcasing its effectiveness in reasoning tasks (Evaluation Results). Building on prior models, DeepSeek R1 integrates Chain-of-Thought (CoT) reasoning, reinforcement learning (RL), and fine-tuning on curated datasets to achieve state-of-the-art performance. This tutorial will walk you through how to deploy DeepSeek R1 from Azure AI Foundry’s model catalog and integrate it with Gradio to build a real-time streaming chatbot specifically for thinking LLMs like DeepSeek R1.
DeepSeek R1 on Azure AI Foundry
On January 29, 2025, Microsoft announced that DeepSeek R1 is now available on Azure AI Foundry and GitHub, making it part of a growing portfolio of over 1,800 AI models available for enterprise use. With this integration, businesses can deploy DeepSeek R1 using serverless APIs, ensuring seamless scalability, security, and compliance with Microsoft’s responsible AI principles. (Azure AI Foundry announcement)

Benefits of Using DeepSeek R1 on Azure AI Foundry
- Enterprise-Ready AI: DeepSeek R1 is available as a trusted, scalable, and secure AI model, backed by Microsoft’s infrastructure.
- Optimized Model Evaluation: Built-in tools allow developers to benchmark performance and compare outputs across different models.
- Security and Responsible AI: DeepSeek R1 has undergone rigorous safety evaluations, including automated assessments, security reviews, and Azure AI Content Safety integration for filtering potentially harmful content.
- Flexible Deployment: Developers can deploy the model via the Azure AI Studio, Azure CLI, ARM templates, or Python SDK.
By combining DeepSeek R1’s robust language understanding with Gradio’s interactive capabilities, you can create a powerful chatbot application that processes and responds to user inputs in real time. This tutorial will walk you through the necessary steps, from setting up the DeepSeek API client to building a responsive Gradio interface, ensuring a comprehensive understanding of the integration process.
Prerequisites
Before we begin, ensure you have the following:
- Python 3.8+ installed on your system.
- An Azure AI Foundry model deployment with an endpoint. If you haven’t deployed DeepSeek R1 as a serverless API yet, please follow the steps outlined in Deploy models as serverless APIs.
- An Azure AI Foundry model deployment with an endpoint.
- The required Python packages installed:
pip install azure-ai-inference gradio - Environment variables set for your Azure AI credentials:
export AZURE_INFERENCE_ENDPOINT="https://your-endpoint-name.region.inference.ai.azure.com" export AZURE_INFERENCE_CREDENTIAL="your-api-key"
Step 1: Setting Up the ChatCompletionsClient
import os
import gradio as gr
from azure.ai.inference import ChatCompletionsClient
from azure.ai.inference.models import SystemMessage, UserMessage, AssistantMessage
from azure.core.credentials import AzureKeyCredential
from gradio import ChatMessage
from typing import Iterator
client = ChatCompletionsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"])
# If you're authenticating with Microsoft Entra ID, use DefaultAzureCredential()
# or other supported credentials instead of AzureKeyCredential.
)
Step 2: Implementing a Streaming Response Function
def stream_response(user_message: str, messages: list) -> Iterator[list]:
if not messages:
messages = []
# Convert Gradio chat history into Azure AI Inference messages
azure_messages = [SystemMessage(content="You are a helpful assistant.")]
for msg in messages:
print(f"Gradio ChatMessage: {msg}") # Debug print
if isinstance(msg, ChatMessage):
azure_msg = UserMessage(content=msg.content) if msg.role == "user" else AssistantMessage(content=msg.content)
elif isinstance(msg, dict) and "role" in msg and "content" in msg:
azure_msg = UserMessage(content=msg["content"]) if msg["role"] == "user" else AssistantMessage(content=msg["content"])
else:
continue
azure_messages.append(azure_msg)
# Ensure only serializable objects are sent to Azure
azure_messages = [msg.dict() if hasattr(msg, "dict") else msg for msg in azure_messages]
response = client.complete(messages=azure_messages, stream=True)
# Initialize buffers
thought_buffer = ""
response_buffer = ""
inside_thought = False
for update in response:
if update.choices:
current_chunk = update.choices[0].delta.content
if "<think>" in current_chunk:
inside_thought = True
print("Entering thought processing mode.")
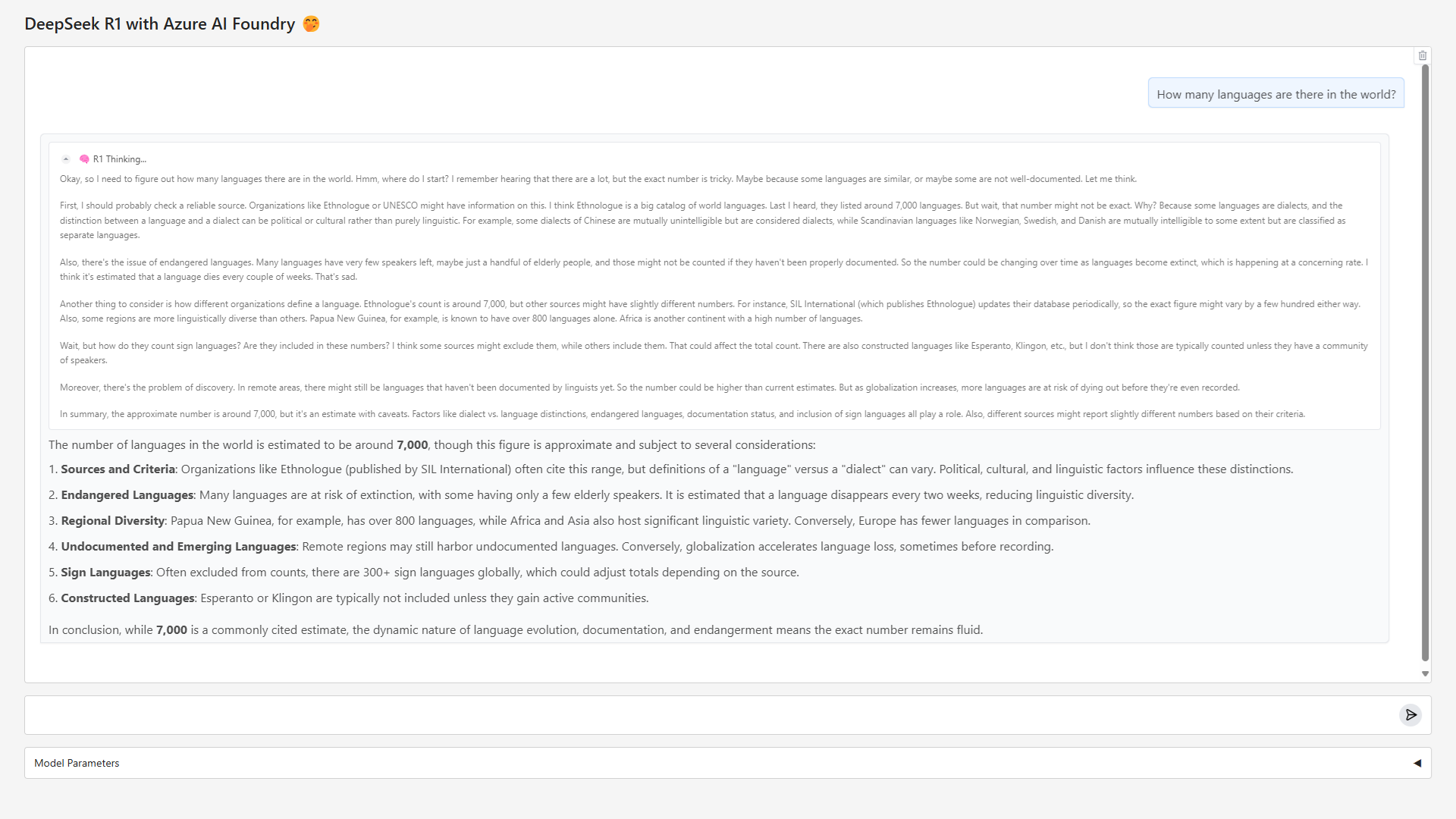
messages.append(ChatMessage(role="assistant", content="", metadata={"title": "🧠 R1 Thinking...", "status": "pending"}))
yield messages
continue
elif "</think>" in current_chunk:
inside_thought = False
messages[-1] = ChatMessage(
role="assistant",
content=thought_buffer.strip(),
metadata={"title": "🧠 R1 Thinking...", "status": "done"}
)
yield messages # Yield the thought message immediately
thought_buffer = ""
continue
if inside_thought:
thought_buffer += current_chunk
messages[-1] = ChatMessage(
role="assistant",
content=thought_buffer,
metadata={"title": "🧠 R1 Thinking...", "status": "pending"}
)
yield messages # Yield the thought message as it updates
else:
response_buffer += current_chunk
if messages and isinstance(messages[-1], ChatMessage) and messages[-1].role == "assistant" and (not messages[-1].metadata or "title" not in messages[-1].metadata):
messages[-1] = ChatMessage(role="assistant", content=response_buffer)
else:
messages.append(ChatMessage(role="assistant", content=response_buffer))
yield messages
Step 3: Creating the Gradio Interface
with gr.Blocks(title="DeepSeek R1 with Azure AI Foundry", fill_height=True, fill_width=True) as demo:
title = gr.Markdown("## DeepSeek R1 with Azure AI Foundry 🤭")
chatbot = gr.Chatbot(
type="messages",
label="DeepSeek-R1",
render_markdown=True,
show_label=False,
scale=1,
)
input_box = gr.Textbox(
lines=1,
submit_btn=True,
show_label=False,
)
msg_store = gr.State("")
input_box.submit(lambda msg: (msg, msg, ""), inputs=[input_box], outputs=[msg_store, input_box, input_box], queue=False)
input_box.submit(lambda msg, chat: (ChatMessage(role="user", content=msg), chat + [ChatMessage(role="user", content=msg)]), inputs=[msg_store, chatbot], outputs=[msg_store, chatbot], queue=False).then(
stream_response, inputs=[msg_store, chatbot], outputs=chatbot
)
demo.launch()
Conclusion
In this tutorial, we built a streaming chatbot using DeepSeek R1 on Azure AI Foundry with Gradio.

We covered:
- Setting up the DeepSeek R1 model on Azure.
- Creating and handling chat completion requests.
- Implementing real-time streaming responses.
- Deploying the chatbot using Gradio.
Get started today by visiting DeepSeek R1 Azure AI Foundry Model Catalog or DeepSeek on GitHub Models.
Happy coding! 🚀